benchmarking llm language instruction following
note: all code can be found in the github repo associated with this here
background
While creating a language-learning webapp (a whole other post likely required for that, but you can find it here) for myself and a few friends to learn Chinese faster, I encountered an interesting constraint.
Fundamentally, I wanted to constrain LLM outputs such that it would be guaranteed to only output text using language that the reader was guaranteed to understand. A simple example of this is if I gave a human the task "Create a story about a dog using only the words "dog," "ate," "the," and "chocolate." A theoretical human with a competent grasp of the human language would then be forced to make a rather morbid story.
This example is rather simple, but what if our list of allowed words scales into the hundreds? the thousands? the hundreds of thousands? This is the exact task that I laid out to solve.
the task
LLMs are generally not very good at following exact language constraints. This is due in large part to them being predictive models, and with them being highly tied to the architecture of their tokenizers. You can see a myriad of classic examples of LLMs failing tasks like "don't use any em dashes in your response" like this one:
 1757215096351_qwsjgz.png
1757215096351_qwsjgz.png
and several similar scenarios of people raging on twitter. To clear things up, I would like to stress that the ability to do this correctly is not directly a measurement of model intelligence, it's more of a reflection of how the model in particular was trained.
There are some particulary clever ways to get around this as well, notably techniques like constrained decoding, the same method used to force an LLM to output a structured object like a JSON. In this, a trie is constructed, which the LLM then "traverses" which defines its allowed output tokens at a given step.
This is also a fine approach, but it has its own tradeoffs. On the bright side, you have 100% guaranteed compliant output, but because you have to run the decoding yourself (running a custom decoder requires access to model output weights), you have to run the model yourself, pay for a server and GPUs to host, and all the pains associated with that. You're also gated to the smartest open-source models you can find, like Qwen (GPT OSS wasn't out yet while I was doing this work).
However, this was the approach I took for the majority of my development time, because (spoiilers) no model at the the time no model could provide satisfactory outputs.
the approach
so I basically took the brute-force approach and just benchmarked them. In 12 languages, I gave LLMs an "allowed words" list that spanned up to 5,000 words in different languages, and checked if their outputs were able to conform to only words in the dataset. To also test instruction-following, I added "target words" which they would also have to try to include in the output.
results
tl;dr the gpt-family killed everyone. I've always had the general sense that this model is ridiculously good at instruction following, and my benchmark of this cemented that idea. Even gpt-oss, which fits on a smartphone, blew away the previous favorites (Qwen and Opus)
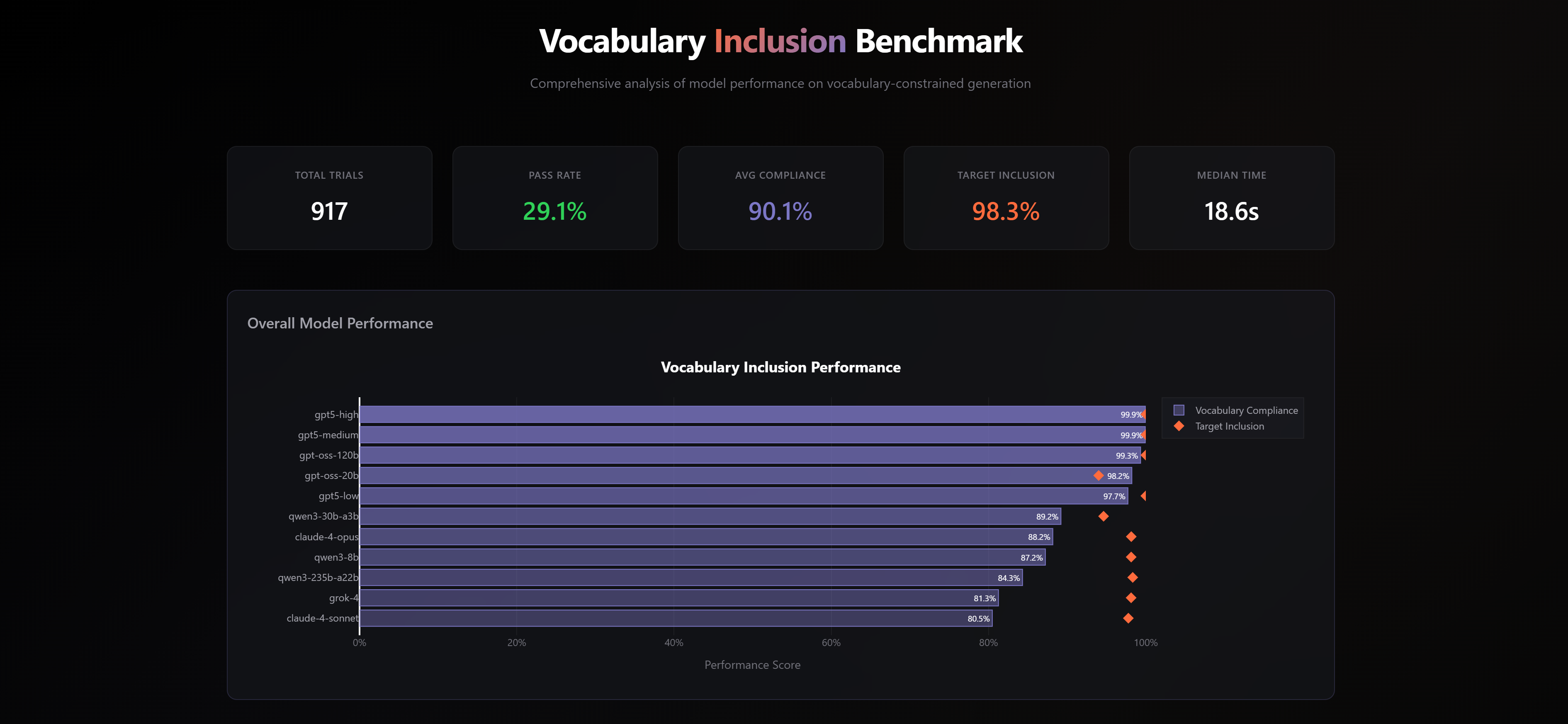 1757215414931_8tgpbe.png
1757215414931_8tgpbe.png
Even more impressively, the variances across trials show that GPT-5 was also vastly more consistent in its outputs.
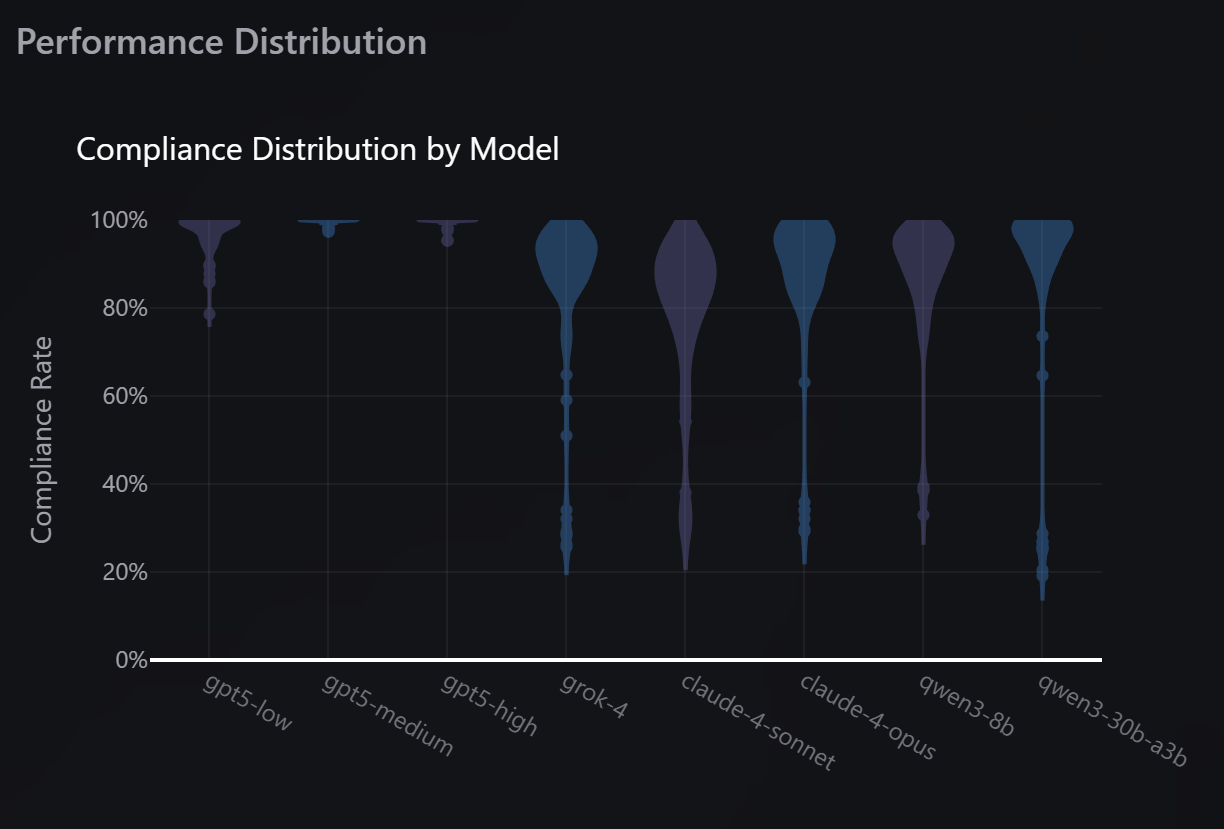 1757215481927_ahkxxv.png
1757215481927_ahkxxv.png
setbacks
I didn't have a metric of how coherent each story was, I may add some self-scoring by an LLM to this later. I did make sure the output tokens were above a certain length, and prompts were strongly encouraging for the story to be 200 words to try to reinforce this. From my eye-test, most model outputs looked reasonable. I also don't read all 12 of these languages however, so that would be up for debate
conclusion
gpt-5 is now my model of choice for constrained text generation. Running a trie-based constrained decoder is no longer worth it when I can abuse openai's server architecture and still get accurate results 99% of the time. languages are rather surprisingly small, and fitting a user's whole vocabulary in context is really no problem for these models either.